
I am a Research Scientist at Google DeepMind . My research focuses on building AI systems for positive-impact applications, most recently climate modeling. Before that, I was a PhD student in the computer vision and machine learning research laboratory (WILLOW project team) in the Department of Computer Science of École Normale Supérieure (ENS) and in Inria Paris where I worked on understanding first person videos under the supervision of Ivan Laptev and Cordelia Schmid. I have received a MS degree in Applied Mathematics from École Centrale Paris and a MS degree in Mathematics, Vision and Learning from ENS Paris-Saclay.
News
Research
arXiv preprint, 2026.
@article{henn2026aimip,
title={AIMIP Phase 1: Systematic Evaluations of AI Weather and Climate Models},
author={Henn, Brian and Bretherton, Christopher S. and Koldunov, Nikolay and Lessig, Christian and Molina, Maria J. and Arcomano, Troy and Watt-Meyer, Oliver and Couairon, Guillaume and Singh, Renu and Brunstein, Robert and Hasson, Yana and Jost, Antonia and Brenowitz, Noah and Manshausen, Peter and Cresswell-Clay, Nathaniel and Durran, Dale and Hall, Kyle Joseph Chen and Yuval, Janni and Kochkov, Dmitrii and Hoyer, Stephan and Lopez-Gomez, Ignacio},
journal={arXiv preprint arXiv:2605.06944},
year={2026}
}
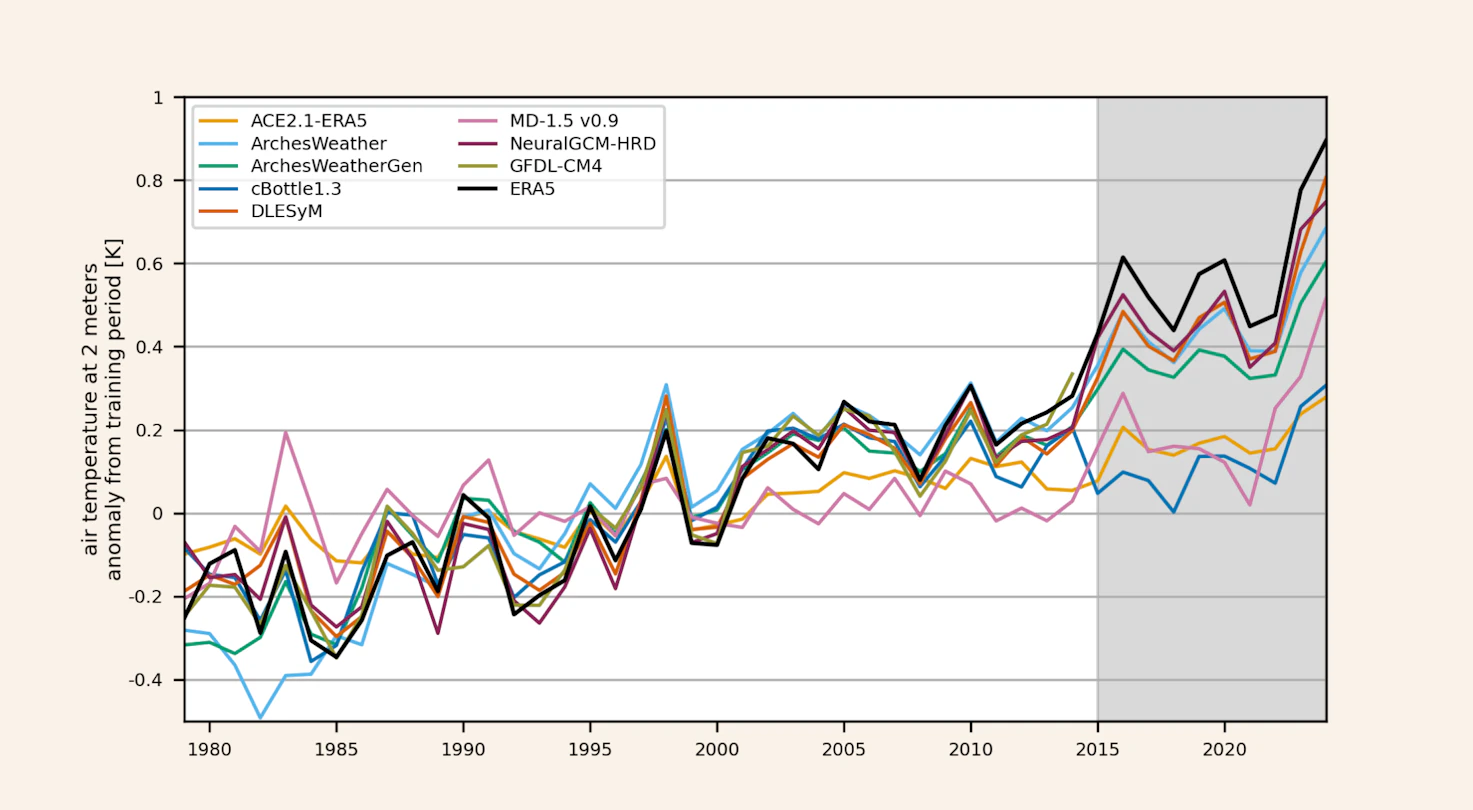
The AI weather and climate model intercomparison project (AIMIP) establishes a standardized framework for evaluating AI-based weather and climate models. Phase 1 assesses participating models trained on ERA5 reanalysis data, tasked with simulating the atmosphere from 1979 to 2024. Models are evaluated across biases, trends, El Niño responses, temporal variability, and out-of-sample generalization.
arXiv preprint, 2026.
@article{singh2026archesweather,
title={Evaluating Skill and Stability of ArchesWeather and ArchesWeatherGen under Multi-Decadal Climate Simulations},
author={Singh, Renu and Brunstein, Robert and Jost, Antonia and Rackow, Thomas and Monteleoni, Claire and Hasson, Yana and Lessig, Christian and Couairon, Guillaume},
journal={arXiv preprint arXiv:2605.29976},
year={2026}
}
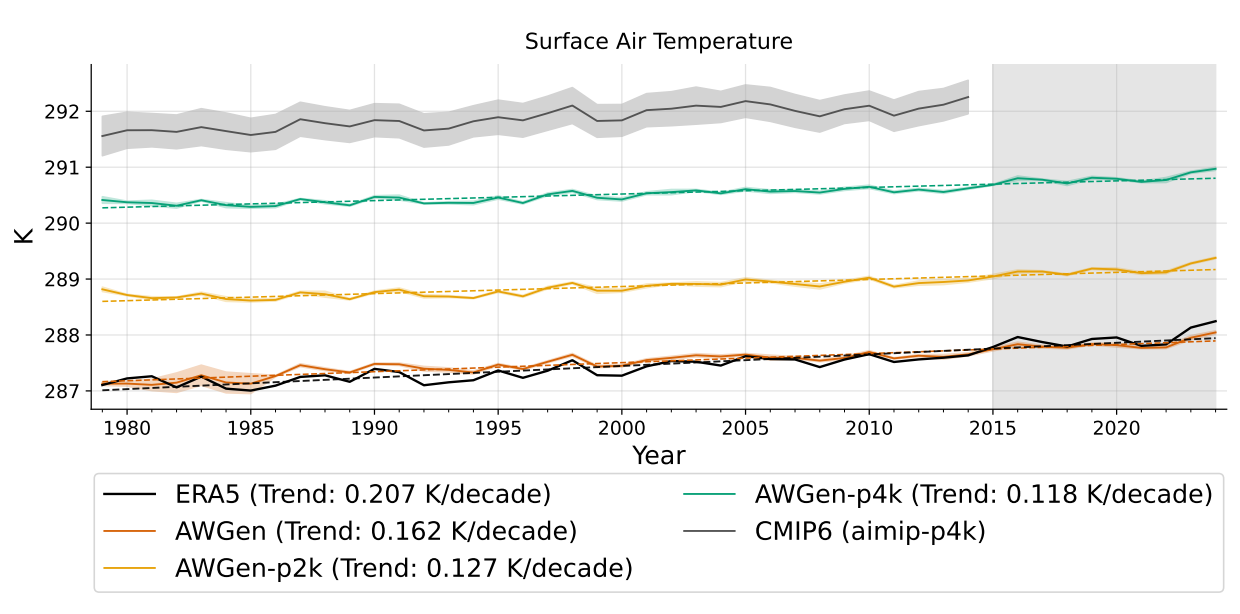
We evaluate ArchesWeather (deterministic) and ArchesWeatherGen (probabilistic flow-matching) when adapted for multi-decadal climate simulation following the AIMIP Phase 1 protocol. Despite their origins in short-term weather forecasting, both models produce stable long-term climate simulations, maintaining a stable annual cycle, capturing climate variable drift, and faithfully reproducing ERA5 climatology, large-scale circulations, and interannual variability.

@article{alayrac2022flamingo,
title={Flamingo: a Visual Language Model for Few-Shot Learning},
author = {Alayrac, Jean-Baptiste and Donahue, Jeff and Luc, Pauline and Miech, Antoine and Barr, Iain and Hasson, Yana and Lenc, Karel and Mensch, Arthur and Millican, Katie and Reynolds, Malcolm and Ring, Roman and Rutherford, Eliza and Cabi, Serkan and Han, Tengda and Gong, Zhitao and Samangooei, Sina and Monteiro, Marianne and Menick, Jacob and Borgeaud, Sebastian and Brock, Andrew and Nematzadeh, Aida and Sharifzadeh, Sahand and Binkowski, Mikolaj and Barreira, Ricardo and Vinyals, Oriol and Zisserman, Andrew and Simonyan, Karen},
journal={arXiv preprint arXiv:2204.14198},
year={2022}
}

3DV, 2021.
@article{{hasson20_homan,
title = {Towards unconstrained joint hand-object reconstruction from RGB videos},
author = {Hasson, Yana and Varol, G"{u}l and Laptev, Ivan and Schmid, Cordelia},
journal ={arXiv preprint arXiv:2108.07044},
year = {2021}
}
Our work aims to obtain 3D reconstruction of hands and manipulated objects from monocular videos. Reconstructing hand-object manipulations holds a great potential for robotics and learning from human demonstrations. The supervised learning approach to this problem, however, requires 3D supervision and remains limited to constrained laboratory settings and simulators for which 3D ground truth is available. In this paper we first propose a learning-free fitting approach for hand-object reconstruction which can seamlessly handle two-hand object interactions. Our method relies on cues obtained with common methods for object detection, hand pose estimation and instance segmentation. We quantitatively evaluate our approach and show that it can be applied to datasets with varying levels of difficulty for which training data is unavailable.
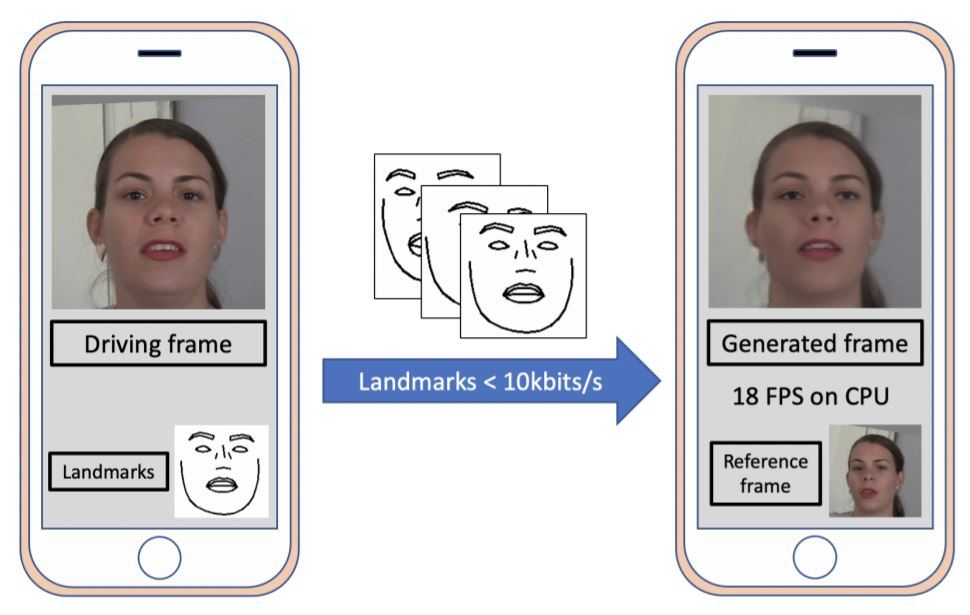
To unlock video chat for hundreds of millions of people hindered by poor connectivity or unaffordable data costs, we propose to authentically reconstruct faces on the receiver's device using facial landmarks extracted at the sender's side and transmitted over the network. In this context, we discuss and evaluate the benefits and disadvantages of several deep adversarial approaches. In particular, we explore quality and bandwidth trade-offs for approaches based on static landmarks, dynamic landmarks or segmentation maps. We design a mobile-compatible architecture based on the first order animation model of Siarohin et al. In addition, we leverage SPADE blocks to refine results in important areas such as the eyes and lips. We compress the networks down to about 3MB, allowing models to run in real time on iPhone 8 (CPU). This approach enables video calling at a few kbits per second, an order of magnitude lower than currently available alternatives.

CVPR, 2020.
@INPROCEEDINGS{hasson20_handobjectconsist,
title = {Leveraging Photometric Consistency over Time for Sparsely Supervised Hand-Object Reconstruction},
author = {Hasson, Yana and Tekin, Bugra and Bogo, Federica and Laptev, Ivan and Pollefeys, Marc and Schmid, Cordelia},
booktitle = {CVPR},
year = {2020}
}
Modeling hand-object manipulations is essential for understanding how humans interact with their environment. While of practical importance, estimating the pose of hands and objects during interactions is challenging due to the large mutual occlusions that occur during manipulation. Recent efforts have been directed towards fully-supervised methods that require large amounts of labeled training samples. Collecting 3D ground-truth data for hand-object interactions, however, is costly, tedious, and error-prone. To overcome this challenge we present a method to leverage photometric consistency across time when annotations are only available for a sparse subset of frames in a video. Our model is trained end-to-end on color images to jointly reconstruct hands and objects in 3D by inferring their poses. Given our estimated reconstructions, we differentiably render the optical flow between pairs of adjacent images and use it within the network to warp one frame to another. We then apply a self-supervised photometric loss that relies on the visual consistency between nearby images. We achieve state-of-the-art results on 3D hand-object reconstruction benchmarks and demonstrate that our approach allows us to improve the pose estimation accuracy by leveraging information from neighboring frames in low-data regimes.

Yana Hasson, Gül Varol, Dimitrios Tzionas, Igor Kalevatykh, Michael J. Black, Ivan Laptev, and Cordelia Schmid
CVPR, 2019.
@INPROCEEDINGS{hasson19_obman,
title = {Learning joint reconstruction of hands and manipulated objects},
author = {Hasson, Yana and Varol, G{\"u}l and Tzionas, Dimitrios and Kalevatykh, Igor and Black, Michael J. and Laptev, Ivan and Schmid, Cordelia},
booktitle = {CVPR},
year = {2019}
}
Code
Miscellaneous
Podcasts I listen to
- Acquired
- Nvidia. Takeaway: Developping hardware in simulation (skipping the prototyping step) *can work* if you have a good simulator... and don't care about one third of your functions crashing.
- TikTok. Takeaway: You can get really far from your starting point when trying to design an educational app.
- WhatsApp.
- Huberman Lab : research-based advice to optimize your body and brain.
- Time Perception & Entrainment by Dopamine, Serotonin & Hormones
- How Foods and Nutrients Control your mood. Takeaway: I now supplement with Omega3.
- Understand & Improve Memory Using Science-Based Tools. Takeaway: Spike your adrenaline close to (at the end or right after) you are processing the information you want to retain (apparently works with information you don't care about too).
- What Alcohol Does to Your Body, Brain & Health. TL;DR: Stay significantly below ~6 drinks a week to avoid numerous health drawbacks.
- In french
- Sexplorer, made by my sister Sophie Hasson
- Passages, des histoires avec plusieurs points de vues.
Articles I enjoyed and/or learned from
- 2022
- A passage to parenthood, by Akhil Sharma the New Yorker
- 2021
- Half a Billion in Bitcoin, Lost in the Dump, by D. T. Max, the New Yorker
- 2020
- Survivors Guilt in the mountains by Nick Paumgarten, the New Yorker.
- The Underground Movement Trying to Topple the North Korean Regime by Suki Kim, the New Yorker.
- How Venture Capitalists Are Deforming Capitalism by Charles Duhigg, the New Yorker. (Rise and fall of wework)
- I Used to Make Fun of Silicon Valley Preppers. Then I Became One. by Nellie Bowles, the New York Times.
- 2019
- The art of decision making, by Joshua Rothman, the New Yorker
- The Age of Instagram Face by Jia Tolentino, the New Yorker
- 2018
- The White Darkness, by David Grann, the New Yorker
- Should We Be Worried About Computerized Facial Recognition?, by David Owen, the New Yorker
- 2017
- The Family That Built an Empire of Pain, by Patrick Radden Keefe, the New Yorker and follow-up The Sackler Family’s Plan to Keep Its Billions
- 2012
- The case against kids, by Elizabeth Kolbert, the New Yorker
- Altered States, by Oliver Sachs, the New Yorker
- 1996
- Into thin air, by Jon Krakauer, Outside Magazine.
Books
- Science fiction short stories
- Isaac Asimov: The Complete Stories by Isaac Asimov (in particular Profession, The Fun They Had and Franchise
- Axiomatic by Greg Egan (in particular Learning to Be Me and Closer)
- Non-fiction
- The Man Who Mistook His Wife for a Hat and Other Clinical Tales, by Oliver Sacks
- When Breath Becomes Air, by Paul Kalanithi
- The Snow Leopard by Peter Matthiessen (non-fiction) and the companion article What Do We Hope to Find When We Look for a Snow Leopard?, by Kathryn Schultz, the New Yorker
- Maus, by Art Spiegelman (Graphic Novel)
- Hiroshima: The Autobiography of Barefoot Gen, by Keiji Nakazawa (Graphic Novel)